Consumer Thread Model
The 2.7.5 version has fully optimized the entire call link. According to the pressure test results, the overall QPS performance has been improved by nearly 30%, and the memory allocation overhead during the call process has also been reduced. One of the design points worth mentioning is that 2.7.5 introduces the concept of Servicerepository, which generates ServiceDescriptor and MethodDescriptor in advance in the service registration phase to reduce resource consumption caused by calculating the original information of the Service in the RPC call phase.
Consumer thread pool model optimization
For Dubbo applications before version 2.7.5, especially some consumer-side applications, when faced with high-traffic scenarios that need to consume a large number of services and have a relatively large number of concurrency (typically such as gateway scenarios), the number of threads on the consumer side is often over-allocated. There are a lot of problems, for specific discussion, please refer to Need a limited Threadpool in consumer side #2013
The improved consumer-side thread pool model solves this problem well by reusing the blocked threads on the business side.
The old thread pool model
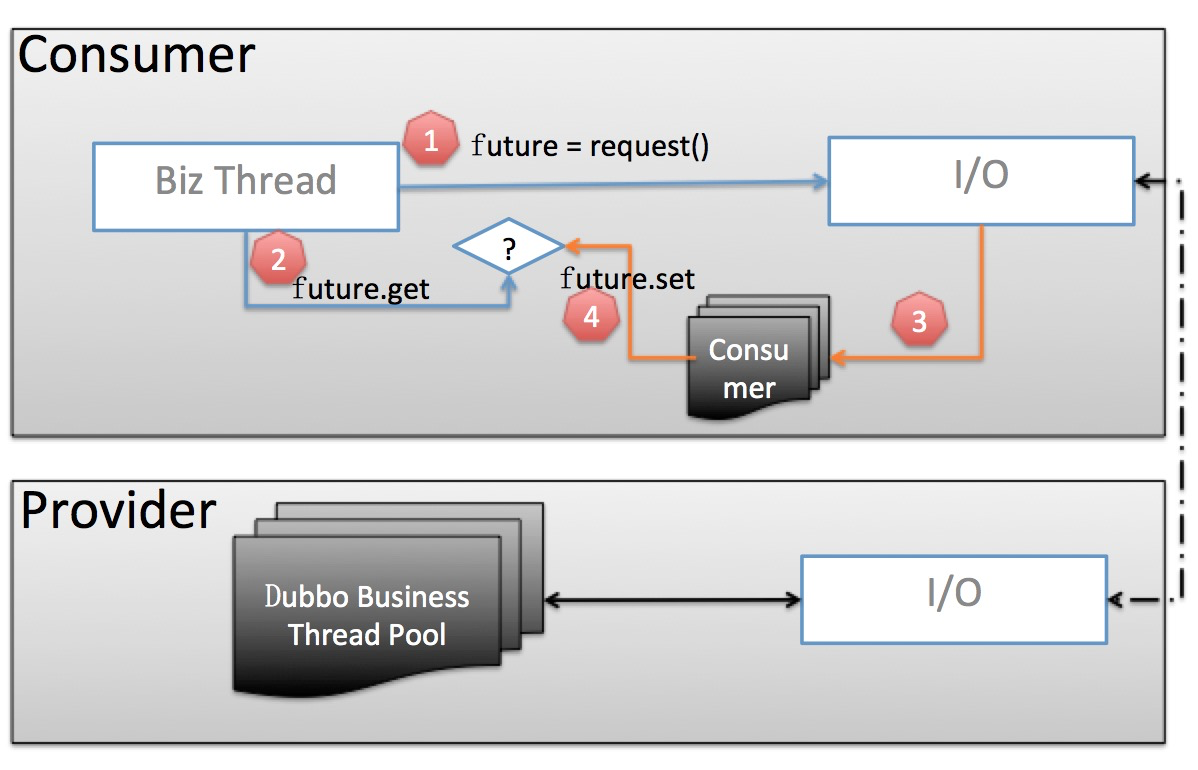
Let’s focus on the Consumer part:
- The business thread sends a request and gets a Future instance.
- The business thread then calls future.get to block and wait for the business result to return.
- When the business data is returned, it will be deserialized by the independent consumer-side thread pool, and future.set will be called to return the deserialized business results.
- The business thread returns directly after getting the result
The thread pool model introduced in version 2.7.5
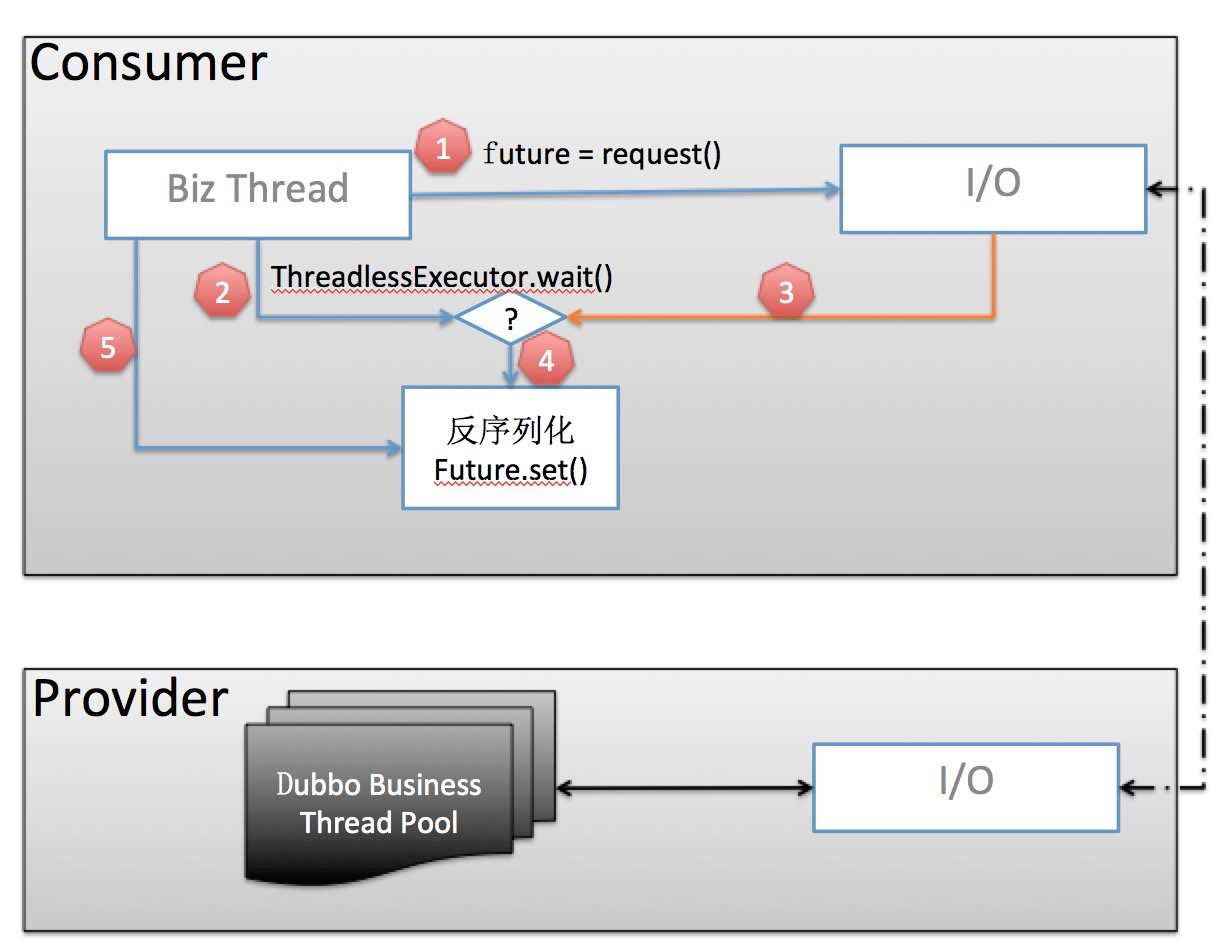
- The business thread sends a request and gets a Future instance.
- Before calling future.get(), call ThreadlessExecutor.wait() first, wait will make the business thread wait on a blocking queue until elements are added to the queue.
- When the business data is returned, generate a Runnable Task and put it into the ThreadlessExecutor queue
- The business thread takes out the Task and executes it in this thread: deserialize the business data and set it to Future.
- The business thread returns directly after getting the result
In this way, compared with the old thread pool model, the business thread itself is responsible for monitoring and parsing the returned results, eliminating the need for additional consumption-side thread pool overhead.
Regarding performance optimization, it will continue to advance in the next version, mainly starting from the following two aspects:
- RPC call link. The points that can be seen so far include: further reducing the memory allocation of the execution link, improving the efficiency of protocol transmission under the premise of ensuring protocol compatibility, and improving the computing efficiency of Filter and Router.
- Service governance link. Further reduce memory and cpu resource consumption caused by address push and service governance rule push.